|
 |
 |
 |
 |
 |
|
 |
 |
 |  |
|
 |
 |
 |
|
|
|
|
 |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
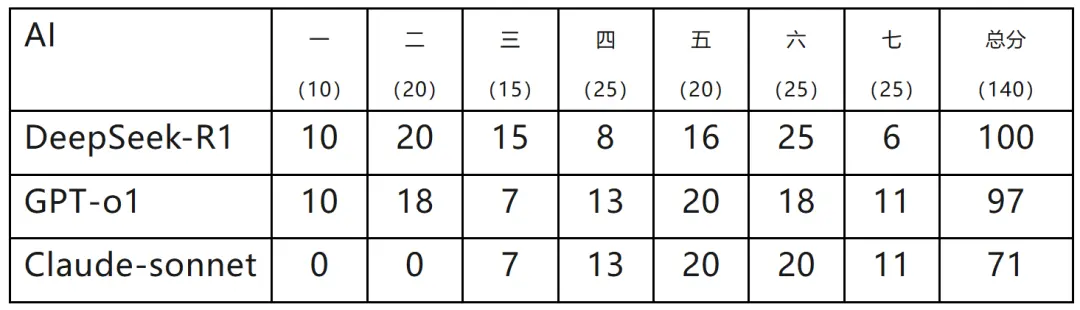
近日,中国“深度求索”公司发布的具备深度思考和推理能力的开源大模型 DeepSeek-R1 受到了全世界的关注。 在 DeepSeek-R1 之前,美国 OpenAI 公司的 GPT-o1,Athropic 公司的 Claude,Google 公司的 Gemini,都号称具备了深度思考和推理能力。这些模型在专业人士和吃瓜网友的五花八门的测试中,表现的确是惊才绝艳。 特别引起我们兴趣的,是 Google 的专用模型 AlphaGeometry 在公认高难度的国际奥林匹克数学竞赛中取得了 28/42 的成绩,获得银牌。学生时代我们也接触过奥数,深知能在此类国际奥赛中获银牌的选手,无一不是从小就体现出相当数学天赋,且一路努力训练的高手。能够达到这个水平的 AI,称其为具备了强大的思考能力并不过分。自打那之后,我们就一直好奇,这些强大的 AI,它们的物理水平又如何? 1 月 17 日,中科院物理所在江苏省溧阳市举办了“天目杯”理论物理竞赛。没过两天, DeepSeek-R1 的发布引爆 AI 圈,它自然成了我们测试的首选模型。此外我们测试的模型还包括:OpenAI 发布的 GPT-o1,Anthropic 发布的 Claude-sonnet。 下面是我们测试的方式: 1.整个测试由 8 段对话完成。 2.第一段对话的问题是“开场白”:交代需要完成的任务,问题的格式,提交答案的格式等。通过 AI 的回复人工确认其理解。 3.依次发送全部 7 道题目的题干,在收到回复后发送下一道题,中间无人工反馈意见。 4.每道题目的题干由文字描述和图片描述两部分组成(第三、五、七题无图)。 5.图片描述是纯文本方式,描述的文本全部生成自 GPT-4o,经人工校对。 6.每个大模型所拿到的文字材料是完全相同的(见附件)。 上述过程后,对于每个大模型我们获得了 7 段 tex 文本,对应于 7 道问题的解答。以下是我们采取的阅卷方式: 1.人工调整 tex 文本至可以用 Overleaf 工具编译,收集编译出的 PDF 文件作为答卷。 2.将 4 个模型的 7 道问题的解答分别发送给 7 位阅卷人组成的阅卷组。 3.阅卷组与“天目杯”竞赛的阅卷组完全相同,且每位阅卷人负责的题目也相同。举例:阅卷人 A 负责所有人类和 AI 答卷中的第一题;阅卷人 B 负责所有人类和 AI 答卷中的第二题,等等。 4.阅卷组汇总所有题目得分。 结果如何呢?请看下表。 结果点评: 1.DeepSeek-R1 表现最好。基础题(前三题分数拿满),第六题还得到了人类选手中未见到的满分,第七题得分较低似乎是因为未能理解题干中“证明”的含义,仅仅重述了待证明的结论,无法得分。查看其思考过程,是存在可以给过程分的步骤的,但最后的答案中这些步骤都没有体现。 2.GPT-o1 总分与 DeepSeek 相差无几。在基础题(二题、三题)中有计算错误导致的失分。相比于 DeepSeek,o1 的答卷更接近于人类的风格,因此以证明题为主最后一题得分稍高。 3.Claude-sonnet 可谓“马失前蹄”,在前两题中连出昏招打了 0 分,但后续表现跟 o1 相当接近,连扣分点都是类似的。 4.如果将 AI 的成绩与人类成绩相比较,则 DeepSeek-R1 可以进入前三名(获特优奖),但与人类的最高分 125 分仍有较大差距;GPT-o1 进入前五名(获特优奖),Claude-sonnet 前十名(获优秀奖)。 最后想聊几句阅卷的主观感想。首先是 AI 的思路是真的好,基本上没有无法下手的题,甚至很多时候一下子就能找到正确的思路。但跟人类不同的是,它们在有正确的思路后,会在一些很简单的错误里面打转。比如通过看 R1 的第七题思考过程,就发现它一早就知道要用简正坐标来做,能想到这一步的考生几乎 100%求解出了正确的简正坐标(一个简单的矩阵对角化而已),但是 R1 似乎是在反复的猜测和试错,到最后也没有得到简正坐标的表达式。 还有就是所有的 AI 似乎都不理解一个“严密”的证明究竟意味着怎样的要求,似乎认为能在形式上凑出答案,就算是证明了。AI 如同人类,也会出现许多“偶然”错误。比如在正式的统一测试前,我们私下尝试过多次,很多时候 Claude-sonnet 可以正确解出第一题的答案,但正式测试的那次它就偏偏做错了。出于严谨,我们也许应该对同一道题测试多次然后取平均,但实在是有点麻烦…… |
 |
 |
 |
 |
 |
 |
 |
Powered by Discuz! X3.4
© 2001-2013 Comsenz Inc.